
Sort by Topics, Resources
Applications
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.


Salto for
Salesforce
Articles
SHARE


Pablo Gonzalez
February 23, 2022
5
min read

Your Salesforce sandbox strategy should consist of two things: selecting the right type of sandbox for each stage of the development lifecycle, and deciding how your metadata changes will move from one sandbox to another until they reach production.
Sounds simple, but like so many things in business systems, it isn’t. It requires that you understand your development lifecycle, what each type of sandbox can and cannot do (I explain all that here in my guide to Salesforce sandboxes), and what type of metadata you want to move and how.
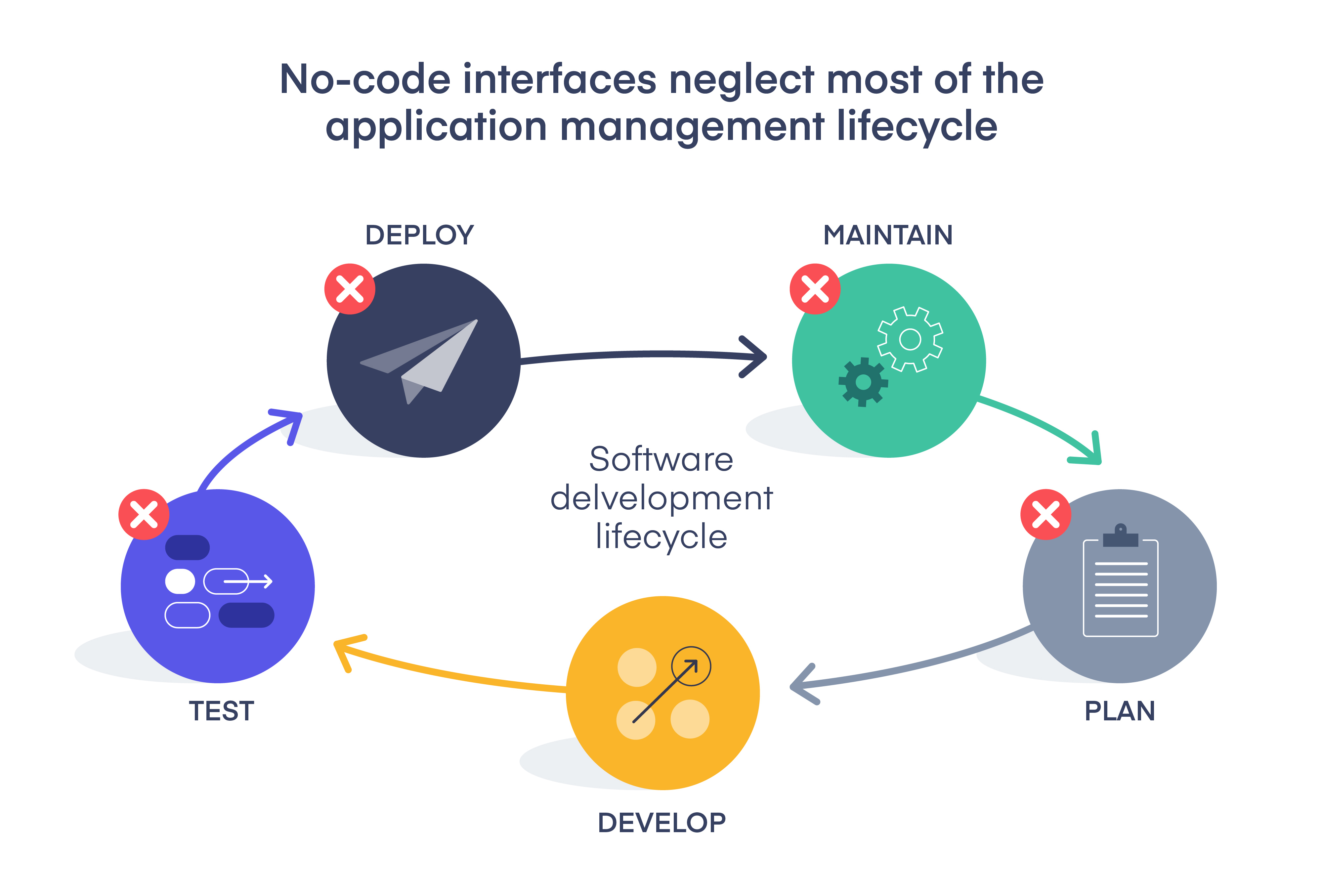
In this guide, I’ll answer the question, “How do I manage multiple sandboxes in Salesforce?” I’ll first show a sample of a simple Salesforce sandbox strategy and then explain why it’s built the way it is. Yours may look different—feel free to customize—but this is a great foundation.

Here’s what’s happening in the above diagram:

There are two approaches:
When every developer has their own sandbox, they have full control over what happens there. They can alter metadata and disable certain features with full confidence that it won't impact others. The sandbox is a safe playground to develop anything.
One challenge is that everyone develops things in slightly different and sometimes in conflicting ways. It’s like a bunch of architects working on pieces of a house, and not comparing notes until it’s time to build. Each developer starts with the same metadata, but develops logic that conflicts with others’ logic. But of course, you always find out the issues in production, when it is, unfortunately, much more difficult to resolve.
Remember this: Early changes are cheap. Late changes are expensive.
To solve the challenge of development “drift” between developer sandboxes, you’ll need to use that integration environment you see pictured, and practice what’s known as continuous integration (CI) to test. By deploying your changes to the integration environment early and often, you can run automated tests and see if your code still works and whether it breaks someone else’s code.
Another challenge this creates is how to pull other developers’ changes back into your own developer environment, but more on that later.
In this setup, all the developers work out of one single sandbox. The advantage of this approach is that by using the same environment, there’s no need for the integration environment sandbox. You are already practicing CI. If your code breaks someone else’s, you’ll both know immediately.
Also, there’s no concern about pulling changes from others’ environments back into yours. That common development environment is the source of truth.
The primary disadvantage to this approach is it provides very little flexibility for experimenting new features or critical changes. Because everyone is working in the same environment, everyone has to communicate very carefully when creating new validation rules or disabling flows. The architectural analogy is that now, every architect is reaching over each other to draw on the same paper schematic. In development, it can feel like you’re walking on eggshells.
I also find this type of sandbox can quickly become riddled with code and automations that are never used, as they were only created for test purposes. This makes it hard to understand what metadata is “structural,” or just there for the purposes of deployment, versus what metadata is just “scaffolding,” just left over from other development activities.
Generally speaking, I recommend Option A. But you’ll have to decide based on your team size and the complexity of your metadata.
A more correct way to phrase this in developer terms is “promote changes” back to lower environments. In essence, as you promote changes from developer sandboxes to higher sandboxes to your production environment, those successive environments become the most current instance.
Let’s say you build a new feature that updates accounts when a salesperson logs a deal, and it changes as it moves through environments. Now it’s live, and if you’re going to develop new things, you need your lower environments (integration, developer) to match production.
This also happens on a smaller scale. Let’s say you’re each working out of your own developer environment, and someone makes an important change in their sandbox. How do you get that change into yours, so you can continue?
There’s no good native way to solve this today in Salesforce. You have to compare the code in each environment, highlight what’s different, copy and paste it. If you’re working with even a medium-sized team, that becomes a very complex equation.
One way to fix this is using Salto’s Compare feature which allows you to compare differences between the integration sandbox and your own, select components you’d like to integrate into your sandbox, and copy it.
Now on to the question of how to move metadata between your sandboxes. If you’ve already played around in Salesforce sandboxes, you’ll know you have four options:
A change set is Salesforce’s most basic mechanism for moving metadata between your environments, and it works great for very small teams. The Force.com Migration Tool and SFDX require a more technical understanding of Salesforce’s APIs and may not be suited for administrators.
When looking for a third-party solution, you typically want something that’s easy to use, yet provides flexibility.
If I can plug Salto here, Salto’s deployment mechanism is very simple and allows you to clone metadata between environments, in any direction you want. You can also see the difference between the environments before you deploy, which helps you understand the impact before you deploy.
Salesforce offers a variety of sandboxes, that range from completely mimicking your production instance (Full Sandbox) on down to having very little production metadata (Developer Sandbox). More metadata is not necessarily better. A Full Sandbox may take days or weeks to refresh depending on complexity, which will certainly slow you down. My rule of thumb: You want the least sandbox necessary for each stage.
In our sample strategy (the diagram above), I chose Developer Sandboxes for the development environment, a Partial Sandbox for the integration environment, and a Full Sandbox for the QA/UAT environment, because that’s what’s needed.
Developer Sandbox: It lacks production data, but you don’t really need it at this point. What you need is a mostly blank canvas where you can build. If you need data for testing, you can always clone a sandbox with existing data or import sample data.
Partial Sandbox: The integration environment should have some data that mirrors the production environment, but does not require everything. You just need to run integration tests to actually use the data in the org, as opposed to data created in Apex test methods.
Full Sandbox: For QA and UAT, you’ll want as complete a sandbox as you can get. The Full Sandbox is a replica of production, and if it works here, it should work there.
You could do much worse than simply copy the sample strategy provided above. I’ve used variations of it often, and it’s a great foundation to build from, provided you answer the important questions:
#1. Give each developer their own sandbox, or have them all work together?
#2. Promote changes back down to lower environments by hand or with a tool?
#3. Promote changes with change sets, Salesforce’s technical options, or a tool?
#4. Implement as recommended, or do something different?

WRITTEN BY OUR EXPERT
Pablo Gonzalez
Business Engineering Architect
Pablo is the developer of HappySoup.io and has 11 years of development experience in all things Salesforce.

© Copyright Salto 2025 | Various trademarks held by their respective owners
Salto for
Salesforce
Salesforce
SHARE
Pablo Gonzalez
February 23, 2022
5
min read
Your Salesforce sandbox strategy should consist of two things: selecting the right type of sandbox for each stage of the development lifecycle, and deciding how your metadata changes will move from one sandbox to another until they reach production.
Sounds simple, but like so many things in business systems, it isn’t. It requires that you understand your development lifecycle, what each type of sandbox can and cannot do (I explain all that here in my guide to Salesforce sandboxes), and what type of metadata you want to move and how.
In this guide, I’ll answer the question, “How do I manage multiple sandboxes in Salesforce?” I’ll first show a sample of a simple Salesforce sandbox strategy and then explain why it’s built the way it is. Yours may look different—feel free to customize—but this is a great foundation.
Here’s what’s happening in the above diagram:
There are two approaches:
When every developer has their own sandbox, they have full control over what happens there. They can alter metadata and disable certain features with full confidence that it won't impact others. The sandbox is a safe playground to develop anything.
One challenge is that everyone develops things in slightly different and sometimes in conflicting ways. It’s like a bunch of architects working on pieces of a house, and not comparing notes until it’s time to build. Each developer starts with the same metadata, but develops logic that conflicts with others’ logic. But of course, you always find out the issues in production, when it is, unfortunately, much more difficult to resolve.
Remember this: Early changes are cheap. Late changes are expensive.
To solve the challenge of development “drift” between developer sandboxes, you’ll need to use that integration environment you see pictured, and practice what’s known as continuous integration (CI) to test. By deploying your changes to the integration environment early and often, you can run automated tests and see if your code still works and whether it breaks someone else’s code.
Another challenge this creates is how to pull other developers’ changes back into your own developer environment, but more on that later.
In this setup, all the developers work out of one single sandbox. The advantage of this approach is that by using the same environment, there’s no need for the integration environment sandbox. You are already practicing CI. If your code breaks someone else’s, you’ll both know immediately.
Also, there’s no concern about pulling changes from others’ environments back into yours. That common development environment is the source of truth.
The primary disadvantage to this approach is it provides very little flexibility for experimenting new features or critical changes. Because everyone is working in the same environment, everyone has to communicate very carefully when creating new validation rules or disabling flows. The architectural analogy is that now, every architect is reaching over each other to draw on the same paper schematic. In development, it can feel like you’re walking on eggshells.
I also find this type of sandbox can quickly become riddled with code and automations that are never used, as they were only created for test purposes. This makes it hard to understand what metadata is “structural,” or just there for the purposes of deployment, versus what metadata is just “scaffolding,” just left over from other development activities.
Generally speaking, I recommend Option A. But you’ll have to decide based on your team size and the complexity of your metadata.
A more correct way to phrase this in developer terms is “promote changes” back to lower environments. In essence, as you promote changes from developer sandboxes to higher sandboxes to your production environment, those successive environments become the most current instance.
Let’s say you build a new feature that updates accounts when a salesperson logs a deal, and it changes as it moves through environments. Now it’s live, and if you’re going to develop new things, you need your lower environments (integration, developer) to match production.
This also happens on a smaller scale. Let’s say you’re each working out of your own developer environment, and someone makes an important change in their sandbox. How do you get that change into yours, so you can continue?
There’s no good native way to solve this today in Salesforce. You have to compare the code in each environment, highlight what’s different, copy and paste it. If you’re working with even a medium-sized team, that becomes a very complex equation.
One way to fix this is using Salto’s Compare feature which allows you to compare differences between the integration sandbox and your own, select components you’d like to integrate into your sandbox, and copy it.
Now on to the question of how to move metadata between your sandboxes. If you’ve already played around in Salesforce sandboxes, you’ll know you have four options:
A change set is Salesforce’s most basic mechanism for moving metadata between your environments, and it works great for very small teams. The Force.com Migration Tool and SFDX require a more technical understanding of Salesforce’s APIs and may not be suited for administrators.
When looking for a third-party solution, you typically want something that’s easy to use, yet provides flexibility.
If I can plug Salto here, Salto’s deployment mechanism is very simple and allows you to clone metadata between environments, in any direction you want. You can also see the difference between the environments before you deploy, which helps you understand the impact before you deploy.
Salesforce offers a variety of sandboxes, that range from completely mimicking your production instance (Full Sandbox) on down to having very little production metadata (Developer Sandbox). More metadata is not necessarily better. A Full Sandbox may take days or weeks to refresh depending on complexity, which will certainly slow you down. My rule of thumb: You want the least sandbox necessary for each stage.
In our sample strategy (the diagram above), I chose Developer Sandboxes for the development environment, a Partial Sandbox for the integration environment, and a Full Sandbox for the QA/UAT environment, because that’s what’s needed.
Developer Sandbox: It lacks production data, but you don’t really need it at this point. What you need is a mostly blank canvas where you can build. If you need data for testing, you can always clone a sandbox with existing data or import sample data.
Partial Sandbox: The integration environment should have some data that mirrors the production environment, but does not require everything. You just need to run integration tests to actually use the data in the org, as opposed to data created in Apex test methods.
Full Sandbox: For QA and UAT, you’ll want as complete a sandbox as you can get. The Full Sandbox is a replica of production, and if it works here, it should work there.
You could do much worse than simply copy the sample strategy provided above. I’ve used variations of it often, and it’s a great foundation to build from, provided you answer the important questions:
#1. Give each developer their own sandbox, or have them all work together?
#2. Promote changes back down to lower environments by hand or with a tool?
#3. Promote changes with change sets, Salesforce’s technical options, or a tool?
#4. Implement as recommended, or do something different?
© Copyright Salto 2025 | Various trademarks held by their respective owners











{kind=link}